Adaptive Scheduler 🚀
🎄🎁 Advent of Open Source – Day 17/24: A tool for efficient, interactive supercomputing from a Jupyter notebook.
(See my intro post)
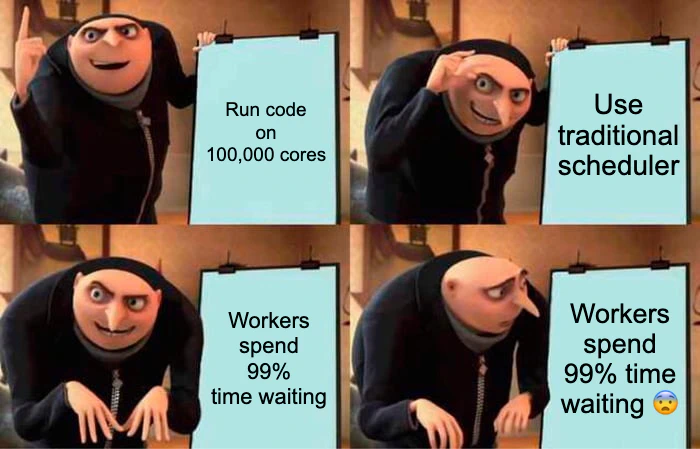
Ever tried to efficiently run 100,000 cores from a Jupyter notebook? No? Well, I have, and it led to some interesting discoveries about the limits of parallel computing tools.
📖 Origin Story
During my 2018 internship at Microsoft Quantum, we faced a unique challenge: our adaptive sampling algorithms needed to run on massive computing clusters (50,000+ cores), but existing tools couldn’t handle it efficiently.
The problem was interesting: traditional parallel computing tools like Dask rely on a central scheduler process. Imagine 100,000 cores, each finishing a task every 10 seconds. That means every 10 microseconds, a core needs new work! With typical scheduler overhead being 1-50 milliseconds, workers would spend 99% of their time waiting rather than computing.
Usually, you’d solve this by batching work ahead of time. But with adaptive sampling (yesterday’s project), that’s impossible - you need the results of previous calculations to know what to compute next. It was like trying to conduct an orchestra where each musician needs personal instructions every few seconds!
🔧 Technical Highlights
We created a solution that:
- Acts as a meta-scheduler, launching multiple sub-schedulers (Dask, ipyparallel, mpi4py, etc.)
- Minimizes communication between scheduling layers
- Handles job management through a simple database
- Supports automatic fault tolerance and data saving
- Works with any cluster scheduler (SLURM, PBS)
- Provides real-time progress tracking in Jupyter notebooks
- Scales to 50,000+ cores without breaking a sweat
📊 Impact
- Used extensively for real quantum device simulations
- 26 GitHub stars (but don’t let that fool you - it’s highly specialized!)
- Enables interactive supercomputing from a simple Jupyter notebook
- Likely ran for many millions of core-hours across various projects
- Actively maintained with 61 releases since 2018, proving its ongoing value
🎯 Challenges We Solved
- Scheduler overhead killing performance at scale
- Data locality and fault tolerance
- Real-time monitoring of massive parallel jobs
- Making supercomputing accessible through notebooks
- Automatic job recovery after crashes (e.g., when using spot VMs or Heisenbugs)
💡 Lessons Learned
- Sometimes you need to think outside the box
- The best tools hide complexity behind simple interfaces
- Real-time feedback is crucial, even for massive computations
- When scaling up 1000x, you often need a completely different approach
- Making things “just work” from a notebook is worth the effort
Want to run massive parallel computations efficiently? Check out Adaptive Scheduler on GitHub!
#OpenSource #Python #HPC #QuantumComputing #ParallelComputing